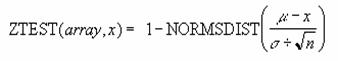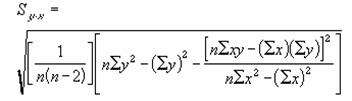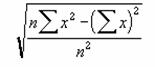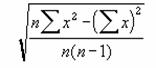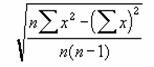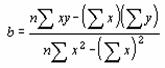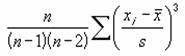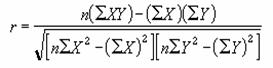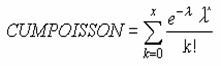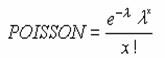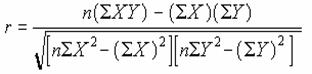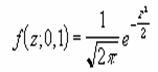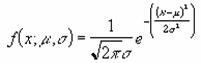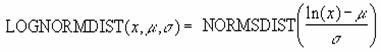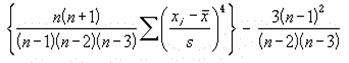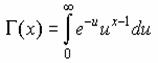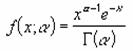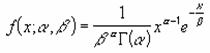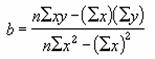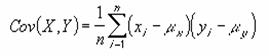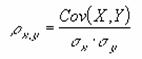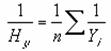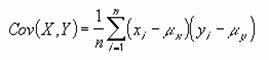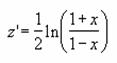Part3
��
�����̎g����
�i���t�@�����X�j
 |
3-1 ���v��
�@���v���́A�f�[�^�͈͂̕��ϒl��ő�ŏ�����l�ȂǁA���v���͂��s�����ł��B��啪��Ɉˑ��������Ȋ��������g�ݍ��܂�Ă��܂��B���Ƃ��A�ݐϊm�����x������z�ȂNJm�������߂���Ȃǂ�����܂��B�Ȃ��A���l�ɑ����ʓI�Ȋ��i���ϒl��ő�ŏ��l�A���ʂȂǁj�ɂ��Ă͂o�������Q�ŏڂ���������Ă���̂ŁA�����ł͏Ȃ��Ă��܂��B
![]()
�@�@ �Q�Q�Q
�����ϒl
���ϒl�����߂铝�v�����Љ�܂��B���l�ɑ����ʓI�ȕ��ϒl��ő�ŏ��l�A���ʂɂ��Ă͂o�������Q�ŏڂ���������Ă���̂ŁA�����ł͏Ȃ��Ă��܂��B
HARMEAN ���l�̒��a���ς�Ԃ��B
DEVSQ �W�{�̕��ϒl����A�f�[�^�̕��̕����a��Ԃ��B
TRIMMEAN �f�[�^�̒��ԍ����ς�Ԃ��B
GEOMEAN ���敽�ς�Ԃ��B
���g�`�q�l�d�`�m��
���l�̒��a���ς�Ԃ��܂��B���߂�l�́A�t���̎Z�p���ρi�������ρj�ɑ���t���Ƃ��Ē�`����܂��B
���� HARMEAN(���l1, ���l2, ...)
���l1,���l2,... �v�Z�̑ΏۂƂȂ�ő�R�O�܂ł̐��l���w�肵�܂��B�z��܂��͔z��ɑ���Z���Q�Ƃ��w�肷�邱�Ƃ��ł���
���̊��͎��̎��Ɠ����Ȓl�Ƃ��ċ��߂��܂��B
���a���ρ������敽�ρ�����������
�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A081Z
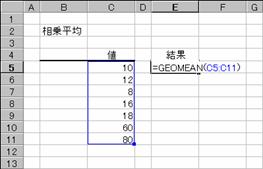
�g�p��
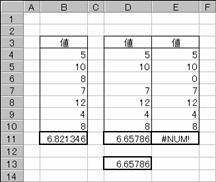
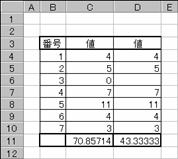
�}�`�͂��ꂼ��̑g�i�f�[�^�W�܂�j�̒��a���ς����߂����ʂł��B�f�[�^�̒��̋Z���͖�������Čv�Z����܂��B�Z���c�P�R�͂c�U�̋��Ȃ����Z���͈͂��w�肵�āA�Z���c�P�P�̑g�S�̂�͈͎w�肵�����ʂƔ�r���Ă��܂��B�g�̒��ɂO�l���邢�͂O�ȉ�������ƌv�Z�s�\�i�G���[�l#NUM!�j���Ԃ���܂��B
�}�`
 �@EX4A165Z
�@EX4A165Z
���͂��鐔��
B11 :=HARMEAN(B4:B10)
D11 :=HARMEAN(D4:D10)
E11 :=HARMEAN(E4:E10)
D13
:=HARMEAN(D4:D5,D7:D10)
���c�d�u�r�p��
�W�{�̕��ϒl�ɑ���e�f�[�^�̕��̕����a��Ԃ��܂��B
���� DEVSQ(���l1, ���l2, ...)
���l1,���l2,... ���̕����a�����߂鐔�l���w�肵�܂��B������1�`30�܂Ŏw��ł��܂��B
���̕����a�́A���̐����ŕ\����܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A068Z
�g�p��
���ϒl�ɑ���e�f�[�^�̕��̕����a�͐}�`�̂悤�ɂȂ�܂��B�Z���b�P�P�̓f�[�^���ɂO���܂ތv�Z���ʂł��B�Z���c�P�P�̓f�[�^���ɋZ�����܂ނƂ��̌��ʁi�r������Čv�Z����Ă���j�ł��B
�}�`
 EX4A167Z
EX4A167Z
���͂��鐔��
C11 :=DEVSQ(C4:C10)
D11 :=DEVSQ(D4:D10)
���s�q�h�l�l�d�`�m��
�����Ɏw�肵���f�[�^�S�̂̏���Ɖ���������̊����̃f�[�^��藎�Ƃ��Ďc��̃f�[�^�̕��ϒl��Ԃ��܂��B
���� TRIMMEAN(�z��, ����)
�z�� �ΏۂƂȂ�f�[�^���܂ރZ���͈͂��w�肵�܂��B
���� ���ϒl�̌v�Z����r������f�[�^�̊����i�O���������P�j�������Ŏw�肵�܂��B
�����m�����n�́A�O�ȏ�P�ȉ��̒l�Ŏw�肵�܂��B���Ƃ��A�S�̂łP�O�̃f�[�^���w�肵�āA�ő�l�ƍŏ��l���Ȃ����f�[�^�̕��ϒl�����߂�ꍇ�A�����ɂO�D�Q���w�肵�܂��B���̌��ʁA�r�������f�[�^�͂P�O�~�O�D�Q=�Q�ƂȂ�������P�A��������P�̍��v�Q�̃f�[�^���r������邱�ƂɂȂ�܂��B
�r�������f�[�^������܂��͏����_�ȉ��̒l���܂ޏꍇ�A��̂Ă��čł��߂��Q�̔{��(����)�ɂ���܂��B���Ƃ��A�f�[�^�̑������P�O�Ŋ����ɂO�D�P���w�肷��ƁA�r�������f�[�^���͂P�O�~�O�D�P=�P�ƂȂ�܂����A���ۂ̌v�Z�ł́A�f�[�^�̔r���͍s���܂���B�܂��A�r�������R�ɂȂ�悤�ȏꍇ�A�������P�A��������P�̂Q�̃f�[�^�������r������܂��B
�g�p��
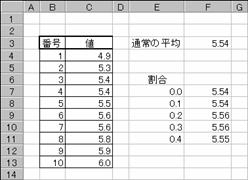
�r���̊������w�肵�����ϒl�����߂�Ɛ}�`�̂悤�ɂȂ�܂��B�Z���e�V�̔r�����͂O�A�Z���e�W�̔r�����͂P�ɂȂ�̂Ŕr�����Ȃ��ŕ��ϒl�����߂��Ă��܂��B�Z���e�X�̔r�����͂Q�A�Z���e�P�O�̔r�����͂R�Ȃ̂ŏ���������ꂼ��P�̃f�[�^��r���������ϒl���v�Z����Ă��܂��B�Z���e�R�͌��ʂ̔�r�p�Ƃ��Ēʏ�̕��ϒl�����߂Ă��܂��B
�}�`
 �@EX4A166Z
�@EX4A166Z
���͂��鐔��
F3 :=AVERAGE(C4:C13)
F7
:=TRIMMEAN($C$4:$C$13,E7)
F8
:=TRIMMEAN($C$4:$C$13,E8)
F9 :=TRIMMEAN($C$4:$C$13,E9)
F10:=TRIMMEAN($C$4:$C$13,E10)
F11:=TRIMMEAN($C$4:$C$13,E11)
���f�d�n�l�d�`�m��
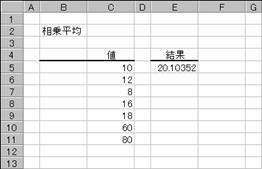
���̐�����Ȃ�z��܂��̓Z���͈͂̃f�[�^�̑��敽�ς�Ԃ��BGEOMEAN ���𗘗p����ƁA�������ϓ�����ꍇ�̕����v�Z�ŁA���ϐ��������v�Z���邱�Ƃ��ł��܂��B
���� GEOMEAN(���l1, ���l2, ...)
���l1,���l2,... ���敽�ς��v�Z���鐔�l���w�肷��i�ő�R�O�j
���敽�ς͎��̎��ŗ^�����܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A080Z
�g�p��
�m�`�n��������͂���
�m�a�n����
 |
 |
 �@
�@
EX4A391Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A392Z
�y�܂Ƃ߁z
HARMEAN ���l�̒��a���ς�Ԃ��܂��B
DEVSQ �W�{�̕��ϒl����A�f�[�^�̕��̕����a��Ԃ��܂��B
TRIMMEAN �f�[�^�̒��ԍ����ς�Ԃ��܂��B
���f�[�^�͈͂̋A������A�_���l�͔r������Čv�Z����܂��B
������
MEDIAN �w�肳�ꂽ���l�̃��W�A����Ԃ��B
MODE �f�[�^�̒��ōł��p�ɂɏo������l (�ŕp�l) ��Ԃ��B
���l�d�c�h�`�m��
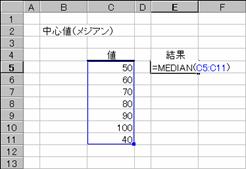
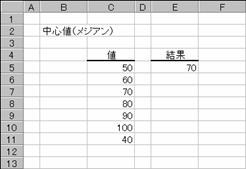
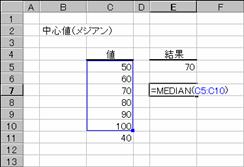
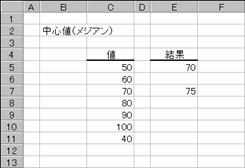
�������X�g�Ɋ܂܂�鐔�l�̃��W�A��(�����l)��Ԃ��B���W�A���Ƃ́A�������X�g�̐��l�����������̂���傫�Ȃ��̂ɏ��ɕ��ׂ��Ƃ��A���̒����ɂ��鐔�l�̂��Ƃł��B
���� MEDIAN(���l1, ���l2, ...)
���l1,���l2,... �v�Z����l���w�肷��i�R�O�܂ł̐��l�j
�����Ƃ��Ďw�肵���l�ɁA������A�_���l�A�܂��͋Z�����܂܂��ꍇ�A�����̒l�͖�������܂��B�������A�l���O�ł���Z���͌v�Z�̑ΏۂɂȂ�܂��B�����Ƃ��Ďw�肵�����l�̌��������ł���ꍇ�A�����Ɉʒu����Q�̐��l�̕��ς��v�Z����܂��B
�g�p��
�m�`�n��������͂���
�m�a�n����
 |
 �@�@
�@�@
EX4A403Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A404Z
���̗�́A�l�̐����U�̋����Ȃ̂ŁA�R�ڂ̂V�O�ƂS�ڂ̂W�O�̕��ϒl�i�V�T�j���Ԃ���Ă��܂��B
�m�`�n��������͂���
�m�a�n����
 �@�@
�@�@
EX4A405Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A406Z
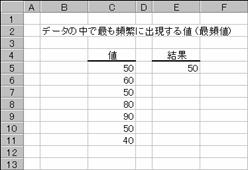
���l�n�c�d��
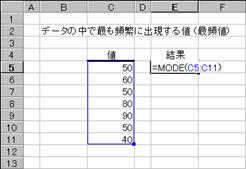
�z��܂��̓Z���͈͂Ƃ��Ďw�肳�ꂽ�f�[�^�̒��ŁA�ł��p�ɂɏo������l(�ŕp�l)��Ԃ��B
���� MODE(���l1, ���l2, ...)
���l1,���l2,... �v�Z����l���w�肷��i�R�O�܂ł̐��l�j
�����Ƃ��Ďw�肵���z���Z���͈͂ɁA������A�_���l�A�܂��͋Z�����܂܂��ꍇ�A�����̒l�͖�������܂��B�������A�l�� 0 �ł���Z���́A�v�Z�̑ΏۂƂȂ�܂��B�ΏۂƂȂ�f�[�^�ɏd������l���܂܂�Ă��Ȃ��ꍇ�A�G���[�l #N/A ���Ԃ���܂��B
�g�p��
�m�`�n��������͂���
�m�a�n����
 �@�@
�@�@
EX4A407Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A408Z
�����K���z��
NORMDIST ���K���z���̒l��Ԃ��B
NORMINV ���K���z���̋t���̒l��Ԃ��B
���m�n�q�l�c�h�r�s��
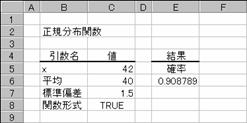
�w�肵�����ςƕW�����ɑ��鐳�K���z���̒l��Ԃ��B���̊��́A����������n�߂Ƃ��铝�v�w�̕��L������ɉ��p�ł��܂��B
���� NORMDIST(x, ����, �W����, ���`��)
x ���ɑ�����鐔�l���w�肷��B
���� ���z�̎Z�p���� (��������) ���w�肷��B
�W���� ���z�̕W�������w�肷��B
���`�� �v�Z�Ɏg�p������̎�ނ��w�肷��
�_���l ���`��
TRUE �ݐϕ��z��
FALSE �m�����x��
���K���z�̊m�����x���͎��̎��Œ�`����܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A094Z
�g�p��
�m�`�n��������͂���
�m�a�n����
 �@�@
�@�@
EX4A410Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A409Z
���m�n�q�l�h�m�u��
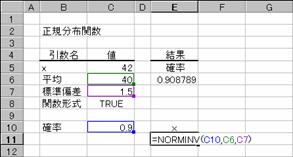
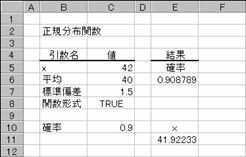
�w�肵�����ςƕW�����ɑ��鐳�K�ݐϕ��z���̋t���̒l��Ԃ��B
���� NORMINV(�m��, ����, �W����)
�m�� ���K���z�ɂ�����m�����w�肷��B
���� ���z�̎Z�p���� (��������) ���w�肷��B
�W���� ���z�̕W�����l���w�肷��B
���l�̌v�Z�ɔ����v�Z�̎�@�����p�����̂ŁA�v�Z���ʂ̐��x���}3x10-7�ȓ��ɂȂ�܂Ŕ����v�Z���s���܂��B100���v�Z���J��Ԃ��Ă��v�Z���ʂ��������Ȃ��ꍇ�A�G���[�l #N/A ���Ԃ���܂��B
�g�p��
�m�`�n��������͂���
�m�a�n����
 �@�@
�@�@
EX4A412Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A411Z
���W�����K�ݐϕ��z��
NORMSDIST �W�����K�ݐϕ��z���̒l��Ԃ��B
NORMSINV �W�����K�ݐϕ��z���̋t���̒l��Ԃ��B
���m�n�q�l�r�c�h�r�s��
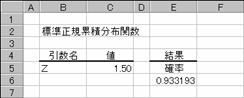
�W�����K�ݐϕ��z���̒l��Ԃ��B���̕��z�́A���ς� 0(�[��) �ŕW������ 1 �ł��鐳�K���z�ɑΉ����܂��B
���� NORMSDIST(z)
z ���ɑ������l���w�肷��B
���K���z�̕W�����x���͎��̎��Œ�`����܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A095Z
�g�p��
�m�`�n��������͂���
�m�a�n����
�m�`�n�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�m�a�n
 �@
�@
EX4A413Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A414Z
���m�n�q�l�r�h�m�u��
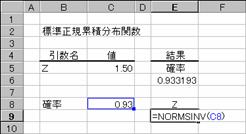
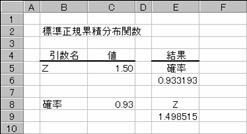
�W�����K�ݐϕ��z���̋t���̒l��Ԃ��B���̕��z�́A���ς� 0 �ŕW������ 1 �ł��鐳�K���z�ɑΉ����܂��B
���� NORMSINV(�m��)
�m�� ���K���z�ɂ�����m�����w�肷��B
�m��<0�A�܂��͊m��>1�ł���ꍇ�A�G���[�l #NUM! ���Ԃ���܂��B�v�Z�ɂ͔����v�Z�̎�@�����p����v�Z���ʂ̐��x���}3x10-7�ȓ��ɂȂ�܂Ŕ����v�Z���s���܂��B100 ���v�Z���J��Ԃ��Ă��v�Z���ʂ��������Ȃ��ꍇ�A�G���[�l #N/A ���Ԃ���܂��B
�g�p��
�m�`�n��������͂���
�m�a�n����
 �@�@
�@�@
EX4A415Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A416Z
���W�����ϗʂƂ�����
STANDARDIZE �W�����ϗʂ�Ԃ��B
ZTEST ������̗����o�l��Ԃ��B
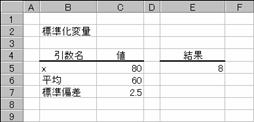
���r�s�`�m�c�`�q�c�h�y�d��
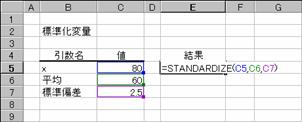
���ςƕW�����Ō��肳��镪�z��ΏۂɁA�W�����ϗʂ�Ԃ��B
���� STANDARDIZE(x, ����, �W����)
x �W�����ϗʂ��v�Z���鐔�l���w�肷��B
���� �ΏۂƂȂ镪�z�̎Z�p(����)���ς��w�肷��B
�W���� �ΏۂƂȂ镪�z�̕W�������w�肷��B
�W�����ϗʂ͎��̎��Œ�`����܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A103Z
�g�p��
�m�`�n��������͂���
�m�a�n����
�m�`�n�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�m�a�n
 �@
�@
EX4A443Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A444Z
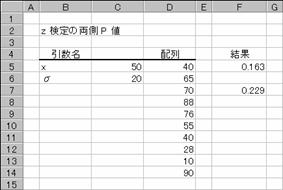
���y�s�d�r�s��
z����̗���P�l��Ԃ��B�z��Ŏw�肳�ꂽ�f�[�^�ɂ���x�̕W���l���v�Z����A���K���z�ɏ]�������̊m�����v�Z����܂��B
���� ZTEST(�z��, x, ��)
�z�� x�̌���ΏۂƂȂ�f�[�^���w�肷��B
x ���肷��l���w�肷��B
�� ��W�c�S�̂Ɋ�Â��W�������w�肷��B
�����Ђ��ȗ�����ƁA�W�{�Ɋ�Â��W�������g�p����܂��B�z��Ƀf�[�^���܂܂�Ă��Ȃ��ꍇ�A�G���[�l #N/A ���Ԃ���܂��B���̊��͎��̂悤�Ȍv�Z���s���܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A116Z
�g�p��
�}�ł͓��������l���Ђ̎w��Əȗ��̗��������߂Ă��܂��B�Z���e�V���ȗ��������̒l�ł��B�Ȃ��A�����m�z��n�����ɒ��ړ��͂���ƈȉ��̂悤�ȏ������ɂȂ�܂��B
���y�s�d�r�s�i�o�S�O�G�U�T�G�V�O�G�W�W�G�V�U�G�T�T�G�S�O�G�Q�W�G�P�O�G�X�O�p�C�b�T�j
 EX4A190Z
EX4A190Z
�e�T�@�F���y�s�d�r�s�i�c�T�F�c�P�S�C�b�T�C�b�U�j
�e�V�@�F���y�s�d�r�s�i�c�T�F�c�P�S�C�b�T�j
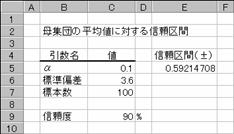
����W�c�̐M�����
CONFIDENCE ��W�c�̕��ϒl�ɑ���M����Ԃ�Ԃ��B
���b�n�m�e�h�c�d�m�b�d��
��W�c�ɑ���M����ԁi�W�{���ς̗����̂���͈́j��Ԃ��B
���� CONFIDENCE(��, �W����, �W�{��)
�� �L�Ӑ������w�肷��i�O�������P�j
�W���� �f�[�^�͈͂ɑ����W�c�̕W�������w�肷��
�W�{�� �W�{���i�f�[�^�͈͂̃f�[�^���j���w�肷��i�����j
�L�Ӑ����͎��̌v�Z�ŋ��߂܂��B�f�[�^�S�̂̐M���x���X�O���̂Ƃ��A
�L�Ӑ������P�|�O�D�X
�@�@�@�@�@�@�@�@���O�D�P
�t�Z�A�L�Ӑ�������M���x�����߂�ɂ́A100 * (1-��)% �Ōv�Z�ł��܂��B
�g�p��
���Џ��i�̎������i�������Ƃ���A�P�O�O�X�܂̕W�{�ŕ��ω��i�����P�C�Q�T�O�~�ɂȂ��W�c�̕W�����͂R�D�U�ɂȂ�܂����B���̐M���x�͂X�O���Ɖ��肷��ƁA��W�c�̕��ςɑ���M����Ԃ��}�`�̂悤�ɋ��߂��܂����B����āA�������i�̏���Ɖ��������̂悤�ɗ\������܂��B
CONFIDENCE(0.1,3.5,100)
= 0.592
= 1250 �} 0.592 �~
= ��1249.4 �` 1250.6�~
 �@EX4A176Z
�@EX4A176Z
���͂��鐔��
E5 :=CONFIDENCE(C5,C6,C7)
C9 :=100*(1-C5)
���s�A�\���̐ϗ����W��
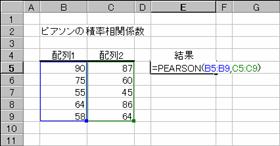
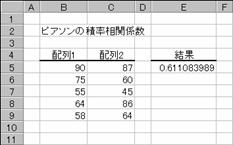
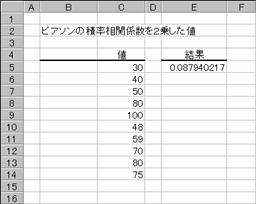
PEARSON �s�A�\���̐ϗ����W���̒l��Ԃ��B
���o�d�`�q�r�n�m��
�s�A�\���̐ϗ����W��r�̒l��Ԃ��B
���� PEARSON(�z��1, �z��2)
�z��1 �����̓Ɨ��ϐ��ɑΉ�����f�[�^���w�肷��
�z��2 �����̏]���ϐ��ɑΉ�����f�[�^���w�肷��
���߂錋�ʂ�r��-1.0����1.0�͈̔͂̐��l�ŁA2�g�̃f�[�^�Ԃł̐��`���ւ̒��x�������܂��B�����Ƃ��Ďw�肵���z��܂��̓Z���͈͂ɁA������A�_���l�A�܂��͋Z�����܂܂�Ă���ꍇ�A�����͖�������܂��B�z��1�Ɣz��2�Ƀf�[�^���܂܂�Ă��Ȃ��Ƃ��A�܂��͗��҂̃f�[�^�̌����قȂ�Ƃ��́A�G���[�l #N/A ���Ԃ���܂��B��A������ r �̒l�͎��̂悤�ɒ�`����Ă��܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A096Z
�g�p��
�m�`�n��������͂���
�m�a�n����
 �@
�@
EX4A417Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A418Z
�����W��
CORREL 2
�̃f�[�^�Ԃ̑��W����Ԃ��B
COVAR �����U (2 �g�̑Ή�����f�[�^�Ԃł̕W�����̐ς̕��ϒl) ��Ԃ��B
FISHER �t�B�b�V���[�ϊ��̒l��Ԃ��B
FISHERINV �t�B�b�V���[�ϊ��̋t���̒l��Ԃ��B
FORECAST ��A������̒l��Ԃ��B
FREQUENCY �f�[�^�̕p�x���z���c�����̔z��Ƃ��ĕԂ��B
���b�n�q�q�d�k��
2�̔z��f�[�^�̑��W����Ԃ��B���W���́A2 �̓����̊W�f����Ƃ��Ɏg�p���܂��B���Ƃ��A�e�n��̐l���Ɛi�w���̑��֊��ׂ邱�Ƃ��ł��܂��B
���� CORREL(�z��1, �z��2)
�z��1 �f�[�^�����͂��ꂽ�Z���͈͂��w�肷��B
�z��2 ��������̃f�[�^�����͂��ꂽ�Z���͈͂��w�肷��B
�f�[�^�ɕ�����A�_���l�A�܂��͋Z�����܂܂��ꍇ�A�����͖�������܂��B�z��1�Ɣz��2�̃f�[�^�̌����قȂ�ƃG���[�l #N/A ���Ԃ���܂��B�f�[�^�̕W������0�ɂȂ�ꍇ�A�G���[�l #DIV/0! ���Ԃ���܂��B���v���͎��̐����Ōv�Z����܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A063Z
������
�܂�
EX4A064Z EX4A065Z
�g�p��
�}�`�̔�r�f�[�^�͈ȉ��̂悤�ɋ��߂��܂��B�ȉ��̐����̓f�[�^��z��萔�œ��͂����������ł��B�}�`�ł̓Z���͈͂Ŏw�肵�Ă��܂��B�i�z��P�͐i�w���i���j�A�z��Q�͐l���i���l�j�Ɖ��肵���Ƃ��̑��W���j
�z��萔���g���ē��͂���ꍇ�̐���
=CORREL({30,20,40,50,60},{29,18,40,60,170})
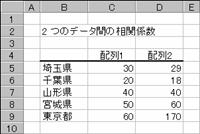 �@EX4A177Z
�@EX4A177Z
���͂��鐔��
F5 :=CORREL(C5:C9,D5:D9)
���b�n�u�`�q��
�����U�A���Ȃ킿�Q�g�̑Ή�����f�[�^�Ԃł̕W�����̐ς̕��ϒl��Ԃ��B
���� COVAR(�z��1, �z��2)
�z��1 �����̃f�[�^�����͂���Ă������̃Z���͈͂��w�肷��B
�z��2 �����̃f�[�^�����͂���Ă����������̃Z���͈͂��w�肷��B
�����Ƃ��Ďw�肳�ꂽ�z��܂��̓Z���Q�Ƃɕ�����A�_���l�A�܂��͋Z�����܂܂��ꍇ�A�����͖�������܂��B�z��1�Ɣz��2�ɓ��͂���Ă���f�[�^�����قȂ�ꍇ�A�G���[�l #N/A ���Ԃ���܂��B�z��1�܂��͔z��2�Ƀf�[�^�����͂���Ă��Ȃ��ꍇ�A�G���[�l #DIV/0! ���Ԃ���܂��B�����U�́A���̐����ŕ\����܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A067Z
�g�p��
�}�`�͈������Z���Q�ƂŎw�肵�����@�A�ȉ��̐����͔z��萔���g�����Ƃ��̏������ł��B
=COVAR({3, 4, 5, 6},
{10, 11, 9, 12})
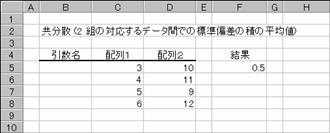 �@EX4A188Z
�@EX4A188Z
F5 :=COVAR(C5:C8,D5:D8)
���e�h�r�g�d�q��
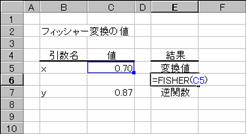
x�̒l�ɑ���t�B�b�V���[�ϊ���Ԃ��B
���� FISHER(x)
x ���ɑ������l���w�肷��B
����x<=-1�܂���x>=1�ł���ꍇ�A�G���[�l #NUM! ���Ԃ���܂��B�t�B�b�V���[�ϊ��́A���̐����ŕ\����܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A071Z
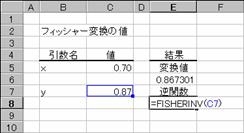
���e�h�r�g�d�q�h�m�u��
�t�B�b�V���[�ϊ��̋t����Ԃ��B
���� FISHERINV(y)
y �t�ϊ��̑ΏۂƂȂ�l���w�肷��B
�t�B�b�V���[�ϊ��̋t���́A���̐����ŕ\����܂��B
�@�@�@�@�@�@�@�@�@�@�@�@EX4A072Z
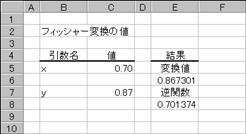
�g�p��
�m�`�n�t�B�b�V���[�ϊ�
�m�a�n�t�B�b�V���[�ϊ��̋t��
�m�b�n����
 |
 �@�@
�@�@
EX4A381Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A382Z
 �@EX4A380Z
�@EX4A380Z
���e�n�q�d�b�`�r�s��
���m�̂��Ɗ��m�̂����瓾�����A����ŁA���̒l�ɑ���]���ϐ��i���j�̒l��\�����܂��B���̊����g���ƁA�����̔��㍂�A���i�ɗʁA������Ȃǂ�\���ł��܂��B
���� FORECAST(x, ���m��y, ���m��x)
x �@ �\������]���ϐ��̒l�ɑ���Ɨ��ϐ��̒l�𐔒l�Ŏw�肷��
���m��y ���m�̏]���ϐ��̒l���w�肷��B
���m��x ���m�̓Ɨ��ϐ��̒l���w�肷��B
���m��y�Ɗ��m��x�Ŏw�肵���Z���͈͂܂��͔z�̂Ƃ��A�܂��͗��҂̃f�[�^�����قȂ�Ƃ��G���[�l #N/A ���Ԃ���܂��B���m��x�Ŏw�肵���f�[�^���ϓ����Ȃ��Ƃ��A�G���[�l
#DIV/0! ���Ԃ���܂��B��������a+bx�ŕ\����܂��B
�@�@�@�@�@�@�@�@�@�@�@�@EX4A076Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A074Z
�g�p��
�m�`�n��������͂���
�m�a�n���ɑ����Z���ɕ��ʂ���
 �@EX4A383Z
�@EX4A383Z
 �@EX4A384Z
�@EX4A384Z
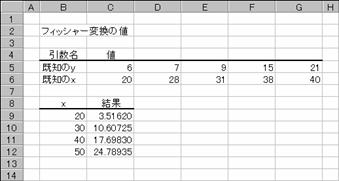
���e�q�d�p�t�d�m�b�x��
�͈͓��̃f�[�^�̕p�x���z���c�����̐��l�̔z��Ƃ��ĕԂ��܂��B���̊��́A���ʂ�z��Ƃ��ĕԂ����z���ɂȂ�܂��B
���� FREQUENCY(�f�[�^�z��, ��Ԕz��)
�f�[�^�z�� �f�[�^�z��܂��̓Z���͈͂��w�肷��
��Ԕz�� �l�̊Ԋu��z��܂��̓Z���͈͂Ŏw�肷��
�g�p��
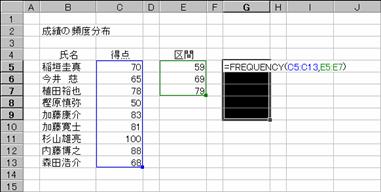
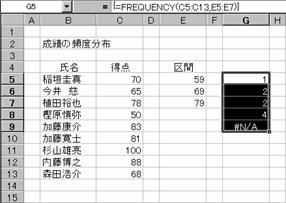
�����̐��т͈͓̔��Ɋ܂܂�鐬�т̕p�x���z�A�܂艽�_�䂪���l�A���v�Z���邱�Ƃ��ł��܂��B�}�̓e�X�g�̌��ʂ���A�O�`�T�X�_�A�U�O�`�U�X�_�A�V�O�`�V�X�_�A�W�O�ȏ�̐l�������߂Ă��܂��B���̊��͔z��`���Ȃ̂ŁA��������͂���O�Ɍ��ʂ�\������͈͂�I����Ԃɂ��邱�ƂƁA�����̓��͌���́m�r�g�h�e�s�n�Ɓm�b�s�q�k�n�L�[�������Ȃ���m�d���������n�L�[���������Ƃ��K�v�ł��B���͌�́��m�^�`�\���͏o�̓f�[�^�����I�������͈͂������������Ƃ������܂��B�}�ł́A��Ԕz����R�����w�肵���̂ŁA�R�͈̔͂Ƃ��̑��̂S���o�͂���邱�ƂɂȂ�A�͈͎w��͂S�̃Z���ŗǂ��������ƂɂȂ�܂��B
�@���ʂ��o�͂���Z���͈͂�I������
�A������͂���
���m�r�g�h�e�s�n�{�m�b�s�q�k�n�{�m�d���������n�L�[������
�m�`�n���������͂���A�e�Z���Ɍ��ʂ��\�������
�m�a�n�͈͂��P�����I�����Ă����̂ŁA�P���̃G���[���\�������
�G���[�̃Z���������폜���邱�Ƃ͂ł��܂���B�Z���͈͂̑I�����琔���̓��͂���蒼���܂��B���ʂ́A��Ԕz��Ɏw�肵�����ɕ\������Ă��܂��B�Z���f�T�͂O�`�T�X�_�̐l���A�Z���f�U�͂U�O�`�U�X�_�A�Z���f�V�͂V�O�`�V�X�_�A�Z���f�W�͂W�O�ȏ�̐l���ɂȂ�܂��B
 �@EX4A534Z
�@EX4A534Z
 �@EX4A535Z
�@EX4A535Z
���͂��ꂽ�����͔z��`���ɂȂ�A�m�b�n�̂悤�ɐ����̑O��Ɂo�p���t�����ꂽ��Ԃœ��͂���܂��B
���w�����z��
EXPONDIST �w�����z���̒l��Ԃ��B
POISSON �|�A�\���m�����z�̒l��Ԃ��B
���d�w�o�n�m�c�h�r�s��
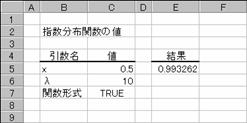
�w�����z����Ԃ��B�C�x���g�Ȃǂ̂��鏈�����s�����߂ɕK�v�Ȏ��ԂȊԊu�����f�����i���Ԉȓ��ɏI������m���j����ꍇ�Ɏg�p���܂��B
���� EXPONDIST(x, ��, ���`��)
x �������l���w�肷��B
�� �p�����[�^�̒l���w�肷��B
���`�� �v�Z�Ɏg�p����w�����̌`����_���l�Ŏw�肷��B
�_���l�@
TRUE �ݐϕ��z���Ōv�Z
FALSE �m�����x���Ōv�Z
����x<0�ł���ꍇ�A�Ɂ���0�ł���ꍇ�A�G���[�l #NUM! ���Ԃ���܂��B�m�����x���͍����A�ݐϕ��z���͉E���ŕ\����܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A069Z�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A070Z
�g�p��
 �@
�@
EX4A375Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A376Z
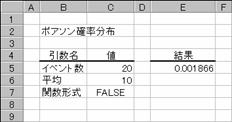
���o�n�h�r�r�n�m��
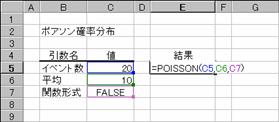
�|�A�\���m�����z�̒l��Ԃ��B
���� POISSON(�C�x���g��, ����, ���`��)
�C�x���g�� ���ۂ̔������w�肷��
���� ���ۂ̕��ϒl���w�肷��
���`�� �m�����z���v�Z������`����_���l�Ŏw�肷��
�_���l
TRUE �ݐσ|�A�\���m�����z���Ōv�Z����
FALSE �|�A�\���m�����x���Ōv�Z����
�C�x���g���ɏ����_�ȉ��̒l���w�肵�Ă���̂Ă��܂��B�C�x���g���܂��͕��ςɐ��l�ȊO�̒l���w�肷��ƁA�G���[�l #VALUE! ���Ԃ���܂��B�C�x���g��<=0 �̏ꍇ�A����<=0�̏ꍇ�A�G���[�l
#NUM!���Ԃ���܂��B���̊��́A���̂悤�Ɍv�Z����܂��B
���`�� = FALSE �̏ꍇ
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A098Z
���`�� =TRUE �̏ꍇ
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A099Z
�g�p��
�m�`�n��������͂���
�m�a�n����
 �@
�@
EX4A419Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A420Z
���e�m�����z�Ƃe����
FDIST F �m�����z��Ԃ��܂��B
FINV F �m�����z�̋t����Ԃ��܂��B
FTEST F ����̌��ʂ�Ԃ��܂��B
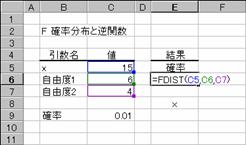
���e�c�h�r�s��
F�m�����z�i2�g�̃f�[�^�̂���j��Ԃ��B
���� FDIST(x, ���R�x1, ���R�x2)
x ���ɑ������l���w�肷��B
���R�x1 ���R�x�̕��q���w�肷��B
���R�x2 ���R�x�̕�����w�肷��B
���R�x1�A���R�x2�ɐ����ȊO�̒l���w�肷��ƁA�����_�ȉ�����̂Ă��܂��B����x<0�ł���ꍇ�A ���R�x1<1�܂��͎��R�x1>=1010�ł���ꍇ�A���R�x2<1�܂��͎��R�x2>=1010�ł���ꍇ�A�G���[�l
#NUM! ���Ԃ���܂��B
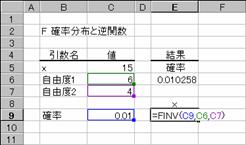
���e�h�m�u��
F�m�����z�̋t����Ԃ��B
���� FINV(�m��, ���R�x1, ���R�x2)
�m�� F �ݐϕ��z�Ɋ֘A����m�����w�肷��B
���R�x1 ���R�x�̕��q���w�肷��B
���R�x2 ���R�x�̕�����w�肷��B
���R�x1�A���R�x2�ɐ����ȊO�̒l���w�肷��ƁA�����_�ȉ�����̂Ă��܂��B�e���������̒l�̂Ƃ��G���[�l #NUM! ���Ԃ���܂��B
�m��<0�܂��͊m��>1�ł���ꍇ
���R�x1 < 1 �܂��� ���R�x1 1010 �ł���ꍇ
���R�x2 < 1 �܂��� ���R�x2 1010 �ł���ꍇ
�g�p��
�m�`�nFDIST��
�m�a�nFINV��
 |
 �@
�@
EX4A379Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A378Z
 �@EX4A377Z
�@EX4A377Z
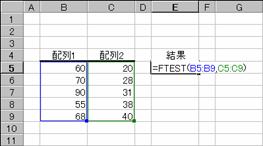
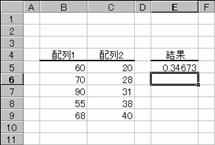
���e�s�d�r�s��
F����̌��ʂ�Ԃ��܂��BF����́A�z��1�Ɣz��2�Ƃ̃f�[�^�̂���ɗL�ӂȍ����F�߂��Ȃ��Б��m�����Ԃ���܂��B
���� FTEST(�z��1, �z��2)
�z��1 ��r�ΏۂƂȂ����̃f�[�^���w�肷��
�z��2 ��r�ΏۂƂȂ��������̃f�[�^���w�肷��
�z��P�܂��͔z��Q�̃f�[�^�����Q�����A���邢�͔z��P�Ɣz��Q�̃f�[�^���܂����������ł���ꍇ�A�G���[�l���c�h�u�^�O�I���Ԃ���܂��B
�g�p��
�m�`�n��������͂���
�m�a�n����
 �@
�@
EX4A538Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A539Z
���K���}��
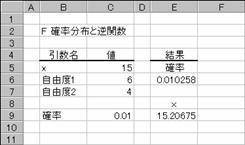
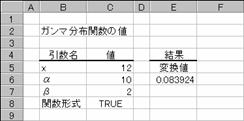
GAMMADIST �K���}���z���̒l��Ԃ��B
GAMMAINV �K���}���z���̋t���̒l��Ԃ��B
GAMMALN �K���}�� ��(x) �̒l�̎��R�ΐ���Ԃ��B
���f�`�l�l�`�c�h�r�s��
�K���}���z���̒l��Ԃ��B���̊��́A���K���z�ɏ]��Ȃ��f�[�^�̕��͂��s���Ƃ��Ɏg���܂��B
���� GAMMADIST(x, ��, ��, ���`��)
x ���ɑ������l���w�肷��B
�� ���z�ɑ���p�����[�^���w�肷��B
�� ���z�ɑ���p�����[�^���w�肷��B
���`�� �Ԃ������l�̌`����_���l�Ŏw�肷��B
�_���l
TRUE �ݐϕ��z�����g��
FALSE �m���ʊ����g��
������=1�ł���ꍇ�A�W���K���}���z�ɏ]�����l���Ԃ���܂��Bx�A���A���ɐ��l�ȊO�̒l���w�肷��ƁA�G���[�l
#VALUE! ���Ԃ���܂��Bx<0�ł���ꍇ�A��<=0�܂��̓�<=0�ł���ꍇ�A�G���[�l
#NUM! ���Ԃ���܂��B�K���}���z�͎��̎��ŗ^�����܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A075Z
�܂��A�W���K���}���z�͎��̎��ŗ^�����܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A076Z
��=1�ł���ꍇ�A���̎����g���Ďw�����z�̒l���v�Z����܂��B
�@�@�@�@�@�@�@�@�@�@�@EX4A077Z
���̐���n�ɑ��āA��=n/2�A��= 2�A���`��=
TRUE�ł���ꍇ�A���R�xn�ɂ�����(1-CHIDIST(x)) �̒l���Ԃ���܂��B
�g�p��
�m�`�n��������͂���
�m�a�n����
 �@
�@
EX4A385Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A386Z
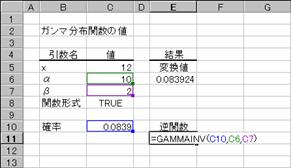
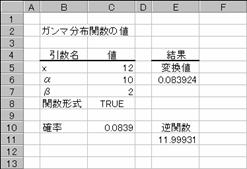
���f�`�l�l�`�h�m�u��
�K���}�ݐϕ��z���̋t���̒l��Ԃ��B
���� GAMMAINV(�m��, ��, ��)
�m�� �K���}�m�����z�ɂ�����m�����w�肷��B
�� �m�����z�̃p�����[�^���w�肷��B
�� �m�����z�̃p�����[�^���w�肷��B
������=1�ł���ꍇ�A�W���K���}���z�̒l���Ԃ���܂��B�m��<0�A�܂��͊m��>1�ł���ꍇ�A��<=0�܂��̓�<=0�ł���ꍇ�A�G���[�l
#NUM! ���Ԃ���܂��B�����v�Z�̎�@�����p�����̂ŁA���x���}3x10-7�ȓ��ɂȂ�܂Ŕ����v�Z���s���܂��B100 ���v�Z���J��Ԃ��Ă��v�Z���ʂ��������Ȃ��ꍇ�A�G���[�l #N/A ���Ԃ���܂��B
�g�p��
���̐}�ł́A��̎g�p��GAMMADIST���ŋ��߂��l���t�Z���Ă��܂��B
�m�`�n��������͂���
�m�a�n����
 �@
�@
EX4A387Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A388Z
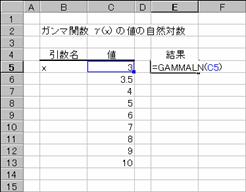
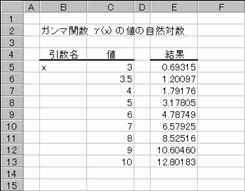
���f�`�l�l�`�k�m��
�K���}�� G(x) �̒l�̎��R�ΐ���Ԃ��B
���� GAMMALN(x)
x ���߂鐔�l���w�肷��
���̊��̒l�́A���̐����Ōv�Z����܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A078Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A079Z
�g�p��
�m�`�n��������͂���
�m�a�n���ɑ����Z���ɕ��ʂ���
�}�`�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�}�a
 �@
�@
EX4A389Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A390Z
���ݐϕ��z��
LOGINV �ΐ����K�ݐϕ��z���̋t���̒l��Ԃ��B
LOGNORMDIST �ΐ����K�ݐϕ��z���̒l��Ԃ��B
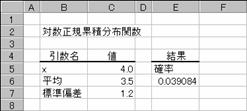
���k�n�f�m�n�q�l�c�h�r�s��
�ΐ����K�ݐϕ��z���̒l��Ԃ��B
���� LOGNORMDIST(x, ����, �W����)
x ���ɑ������l���w�肷��B
���� In (x) (x �̎��R�ΐ�) �̕��ϒl���w�肷��B
�W���� ln (x) (x �̎��R�ΐ�) �̕W�������w�肷��B
�ΐ����K���z���͎��̂悤�ɒ�`����Ă��܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A092Z
�g�p��
�m�`�n��������͂���
�m�a�n����
 �@
�@
EX4A399Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A400Z
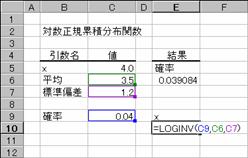
���k�n�f�h�m�u��
�ΐ����K�^�̗ݐϕ��z���̋t����Ԃ��B�ΐ����K�^���z�́A�ΐ��I�ɕϊ����ꂽ�f�[�^�͂���ꍇ�Ɏg�p���܂��B
���� LOGINV(�m��, ����, �W����)
�m�� �ΐ����K�^���z�ɔ����m�����w�肷��B
���� ln(x) �̕��ϒl���w�肷��B
�W���� ln(x) �̕W�������w�肷��B
�ΐ����K�^���z���̋t���́A���̐����ŕ\����܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A091Z
�m�������O�܂��͊m�������P�ł���ꍇ�A�W���������O�ł���ꍇ�A�G���[�l���m�t�l�I���Ԃ���܂��B
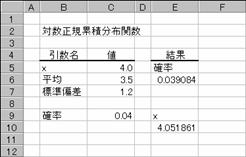
�g�p��
���̗�́ALOGNORMDIST���ŋ��߂��m�����炘�l���t�Z���Ă��܂��B
�m�`�n��������͂���
�m�a�n����
 �@�@
�@�@
EX4A401Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A402Z
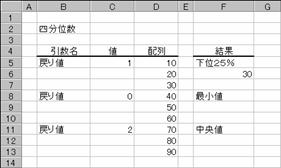
���l���ʐ�
���p�t�`�q�s�h�k�d��
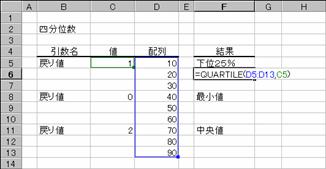
�z��Ɋ܂܂��f�[�^����l���ʐ��𒊏o���܂��B
���� QUARTILE(�z��, �߂�l)
�z�� �ΏۂƂȂ鐔�l�f�[�^���w�肷��B
�߂�l �߂�l�Ƃ��ĕԂ����l���ʐ��̓��e�𐔒l�Ŏw�肷��
�߂�l ����
0 �f�[�^�̍ŏ��l
1 ����4����1(25%)
2 �f�[�^�̒����l(50%)
3 ���4����1(75%)
4 �f�[�^�̍ő�l
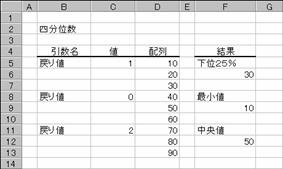
�z��Ƀf�[�^���܂܂�Ă��Ȃ��Ƃ��A�܂��͔z��ɂW�P�X�P����f�[�^���܂܂�Ă���Ƃ��A�G���[�l�@���m�t�l�I���Ԃ���܂��B�߂�l�ɏ����_�ȉ��̒l���w�肵�Ă���̂Ă��܂��B�߂�l���O�܂��͖߂�l���S�̏ꍇ�A�G���[�l���m�t�l�I���Ԃ���܂��B�߂�l�ɂO�A�Q�A�S�̂����ꂩ�̐��l���w�肷��ƁA���ꂼ��l�h�m���A�l�d�c�h�`�m���A�l�`�w���̖߂�l�ɓ������Ȃ�܂��B
�g�p��
�m�`�n�f�[�^�͈͂̉���4����1(25%)�����߂鐔��
�m�a�n����
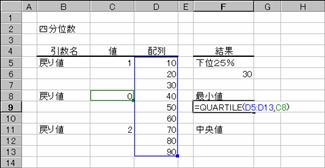
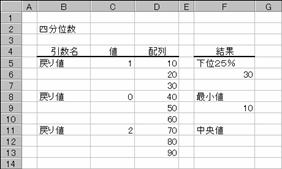
�m�b�n�f�[�^�͈͂̍ŏ��l�����߂鐔��
�m�c�n����
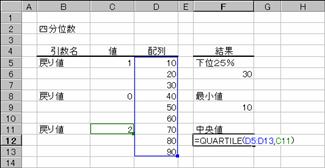
�m�d�n�f�[�^�͈͂̒����l�����߂鐔��
�m�e�n����
�m�`�n�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�m�a�n
 �@
�@
EX4A431Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A432Z
�m�b�n�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�m�c�n
 �@
�@
EX4A433Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A434Z
�m�d�n�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�m�e�n
 �@
�@
EX4A435Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A436Z
��RANK��
�͈͓��̐��l�����ԖڂɈʒu���邩��Ԃ��B
���� RANK(���l, �͈�, ����)
���l �͈͓��ł̏���(�ʒu)�ׂ鐔�l���w�肷��B
�͈� ���l���܂ރZ���͈͂̎Q�Ƃ܂��͖��O�A�܂��͐��l�z����w�肷��B
���� �͈͓��̐��l����בւ�����@���w�肷��B
���� ����
0 �~���ɕ��בւ��i�ȗ��j
�P���邢�͂O�ȊO �����ŕ��בւ�
�����m�͈́n���Ɋ܂܂�Ă��鐔�l�������v�Z�̑ΏۂƂȂ�A�����Ɋ܂܂�Ă��镶����A�Z���A�_���l�͖�������܂��B�܂��A�͈͓��ɃG���[�l���܂܂�Ă���ƁA���̃G���[�l���Ԃ���܂��B
�d���������l�͓������ʂƌ��Ȃ���A����ȍ~�̐��l�̏��ʂ�����܂��B���Ƃ��A10��2�x����A���̏��ʂ�5�ł���Ƃ��A11�̏��ʂ�7�ƂȂ�܂� (���ʂ�6������)�B
�g�p��
�m�`�n��������͂���
�m�a�n���ɑ����Z���ɕ��ʂ���
�m�b�n����
����A����
RSQ �s�A�\���̐ϗ����W���� 2 �悵���l��Ԃ��B
SLOPE ��A�����̌X����Ԃ��B
SKEW ���z�̘c�x��Ԃ��B
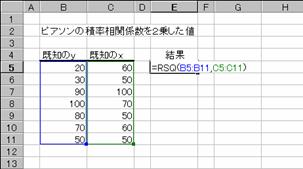
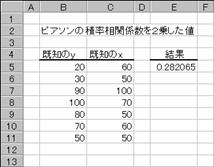
���q�r�p��
���m��y�Ɗ��m��x��ʉ߂����A������ΏۂɁAr2�̒l��Ԃ��B
���� RSQ(���m��y, ���m��x)
���m��y ������A�̃f�[�^���܂ޔz��܂��̓Z���͈͂��w�肷��
���m��x ������A�̃f�[�^���܂ޔz��܂��̓Z���͈͂��w�肷��
��A������r�̒l�͎��̂悤�ɒ�`����܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A100Z
�g�p��
�m�`�n��������͂���
�m�a�n����
 �@
�@
EX4A437Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A438Z
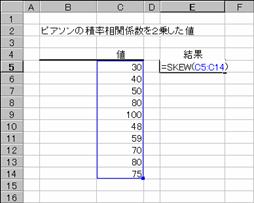
���r�j�d�v��
���z�̘c�x��Ԃ��B�c�x�Ƃ́A���z�̕��ϒl���ӂł̗����̔�Ώ̓x��\���l�ł��B���̘c�x�͑Ώ̂ƂȂ镪�z�����̕����A���̘c�x�͑Ώ̂ƂȂ镪�z�����̕����A�̐L�т������܂��B
���� SKEW(���l1, ���l2, ...)
���l1, ���l2... ���z�̘c�x���v�Z����l���w�肷��i�ő�R�O�܂Łj
���z�̘c�x�͎��̎��Œ�`����܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A101Z
�g�p��
�m�`�n��������͂���
�m�a�n����
�m�`�n�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�m�a�n
 �@�@
�@�@
EX4A439Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A440Z
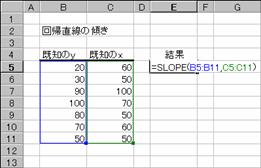
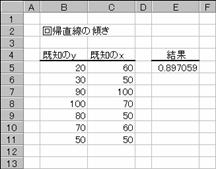
���r�k�n�o�d��
���m��y �� ���m��x �̃f�[�^�����A�����̌X���i�Q�_�Ԃ����Ԓ�����̐��������̋����𐅕������̋����ŏ��Z�����l�j��Ԃ��B
���� SLOPE(���m��y, ���m��x)
���m��y �]���ϐ��̒l���܂ސ��l�z��܂��̓Z���͈͂��w�肷��
���m��x �Ɨ��ϐ��̒l���܂ސ��l�z��܂��̓Z���͈͂��w�肷��
��A�����̌X���͎��̂悤�ɒ�`����܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A102Z
�g�p��
�m�`�n��������͂���
�m�a�n����
�m�`�n�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�m�a�n
 �@�@
�@�@
EX4A441Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A442Z
���W����
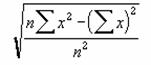
STDEV ��W�c�̕W�{���g���ĕW������Ԃ��B
STDEVA ���l�A������A����ј_���l���܂ޕ�W�c�̕W�{���g���ĕW������Ԃ��B
STDEVP ��W�c�S�̂�ΏۂɕW������Ԃ��B
STDEVPA ���l�A������A����ј_���l���܂ޕ�W�c�S�̂�ΏۂɕW������Ԃ��B
STEYX ��A�����̌ʂ� x �̒l�ɑ��� y �̗\���l�̕W���덷��Ԃ��B
�m�W�����n
���v�I�ȑΏۂƂȂ�l�����̕���(����)����ǂꂾ���L���͈͂ɕ��z���Ă��邩���v�ʂ������̂ł��B
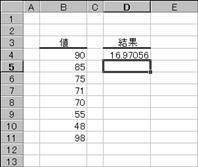
���r�s�c�d�u��
�������W�c�̕W�{�ł���ƌ��Ȃ��āA��W�c�ɑ���W������Ԃ��B
���� STDEV(���l1, ���l2, ...)
���l1, ���l2, ... ��W�c�̕W�{�ɑΉ����鐔�l���w�肷��i�ő�R�O�܂Łj
���l�Ƃ��ĕ�����A�_���l�A�Z���̎Q�Ƃ��w�肷��ƁA�G���[�ɂȂ�܂��B�_���l�iTRUE�AFALSE�Ȃǁj�A����ѕ�����͖�������܂��B���̐������g���ĕW�������v�Z����܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A104Z
�g�p��
�m�`�n��������͂���
�m�a�n����
 �@�@
�@�@
EX4A540Z�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A541Z
���r�s�c�d�u�`��
�W�{�Ɋ�Â��ĕW�������v�Z���܂��B�������ATRUE�AFALSE �Ȃǂ̘_���l���v�Z�̑ΏۂƂȂ�܂��B
���� STDEVA(���l1, ���l2,...)
���l1, ���l2, ... ��W�c�̕W�{�ɑΉ����鐔�l���w�肷��i�ő�R�O�܂Łj
���̐������g���ĕW�������v�Z���܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A105Z
�g�p��
�m�`�n��������͂���
�m�a�n����
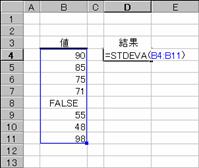 �@�@
�@�@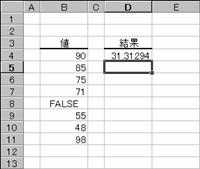
EX4A542Z�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A543Z
���r�s�c�d�u�o��
�������W�c�S�̂ł���ƌ��Ȃ��ĕ�W�c�̕W������Ԃ��B
���� STDEVP(���l1, ���l2, ...)
���l1, ���l2, ... ��W�c�̕W�{�ɑΉ����鐔�l���w�肷��i�ő�R�O�܂Łj
�v�Z�̑Ώۂɕ������_���l�͊܂܂�܂���B���̊��͎��̐������g���ĕW�������v�Z���܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A106Z
�g�p��
�m�`�n��������͂���
�m�a�n����
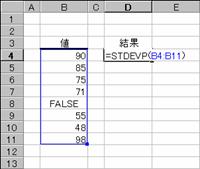 �@�@
�@�@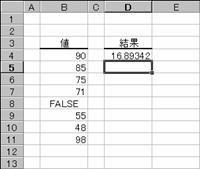
EX4A544Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A545Z
���r�s�c�d�u�o�`��
�������_���l���܂ވ������W�c�S�̂ƌ��Ȃ��āA�W�������v�Z���܂��B
���� STDEVPA(���l1, ���l2,...)
���l1, ���l2, ... ��W�c�̕W�{�ɑΉ����鐔�l���w�肷��i�ő�R�O�܂Łj
������TRUE���܂܂��ꍇ��1�A������܂���FALSE���܂܂��ꍇ��0(�[��)�ƌ��Ȃ���܂��B�v�Z�̑Ώۂɕ������_���l���܂߂Ȃ��ꍇ�́ASTDEVP�����g�p���܂��B���̊��͎��̐������g���ĕW�������v�Z���܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A107Z
�g�p��
�m�`�n��������͂���
�m�a�n����
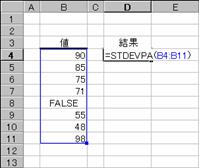 �@�@
�@�@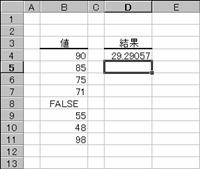
EX4A546Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A547Z
���r�s�d�x�w��
��A�����̕W���덷��Ԃ��B�W���덷�Ƃ́A�ʂ�x�̒l�ɑ���y�̗\���l�̌덷�̒��x���v�����邽�߂̎ړx�ł��B
���� STEYX(���m��y, ���m��x)
���m��y �]���ϐ��̒l��z��܂��̓Z���͈͂Ŏw�肷��
���m��x �Ɨ��ϐ��̒l��z��܂��̓Z���͈͂Ŏw�肷��
y�̗\���l�̕W���덷�͎��̂悤�ɒ�`����܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A108Z
�g�p��
�m�`�n��������͂���
�m�a�n����
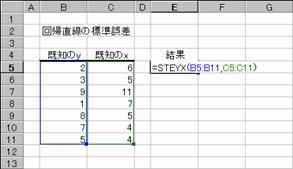 �@�@
�@�@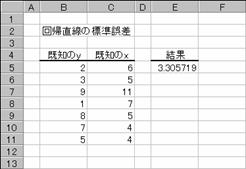
EX4A427Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A428Z
���X�`���[�f���g��t���z
�X�`���[�f���g�̂����z�ɊW������͎��̂R������܂��B
TDIST�� �X�`���[�f���g�̂����z�̒l��Ԃ�
TINV�� �X�`���[�f���g�̂����z�̋t���̒l��Ԃ�
TTEST�� �X�`���[�f���g�̂����z�ɏ]���m����Ԃ�
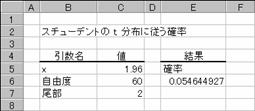
���s�c�h�r�s��
�X�`���[�f���g�� t ���z��Ԃ��B
���� TDIST(x, ���R�x, ����)
x t ���z���v�Z���鐔�l���w�肷��B
���R�x ���z�̎��R�x�𐮐��Ŏw�肷��B
���� �����̕��z���@���w�肷��
�����@�@���z
�@1 �Б����z
�@ �@2 �������z
TDIST���́ATDIST=p(x<X)�Ƃ��Čv�Z����܂��B�����ŁAX �� t ���z�ɏ]�������_���ȕϐ��ł��B
�g�p��
�m�`�n��������͂���
�m�a�n����
 �@�@
�@�@
EX4A423Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A424Z
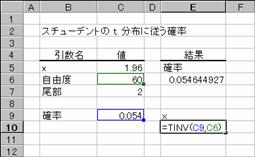
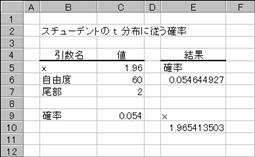
���s�h�m�u��
���R�x���w�肵�āA�X�`���[�f���g�� t ���z�̋t���̒l��Ԃ��B
���� TINV(�m��, ���R�x)
�m�� �X�`���[�f���g�̗���
t ���z�ɏ]���m�����w�肷��B
���R�x ���z�̎��R�x���w�肷��B
���l�̌v�Z�ɔ����v�Z�̎�@�����p�����̂ŁA�v�Z���ʂ̐��x���}3x10-7�ȓ��ɂȂ�܂Ŕ����v�Z���s���܂��B100���v�Z���J��Ԃ��Ă��v�Z���ʂ��������Ȃ��ꍇ�A�G���[�l#N/A���Ԃ���܂��B
�g�p��
�m�`�n��������͂���
�m�a�n����
 �@
�@
EX4A425Z�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A426Z
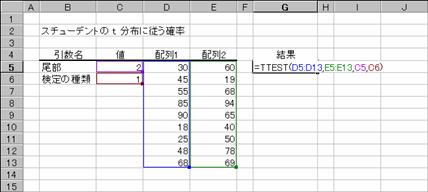
���s�s�d�r�s��
�X�`���[�f���g�� t ���z�ɏ]���m����Ԃ��B
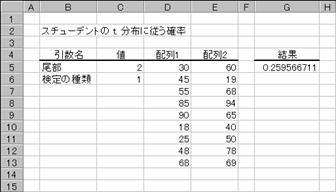
���� TTEST(�z��1, �z��2, ����, ����̎��)
�z��1 �P�ڂ̑g�̃f�[�^���܂ޔz��܂��̓Z���͈͂��w�肷��
�z��2 �Q�ڂ̑g�̃f�[�^���܂ޔz��܂��̓Z���͈͂��w�肷��
���� �����̕��z���@���w�肷��
�����@�@���z
�@1 �Б����z
�@ �@2 �������z
����̎�� ���s���� t ����̎�ނ𐔒l�Ŏw�肷��B
����̎�� ����
1
���Ȃ��f�[�^�� t ����
2 �����U�� 2 �W�{��ΏۂƂ��� t
����
3 ���U�� 2 �W�{��ΏۂƂ��� t
����
�g�p��
�m�`�n��������͂���
�m�a�n����
 �@EX4A421Z
�@EX4A421Z
 �@EX4A422Z
�@EX4A422Z
���f�[�^�̐�x
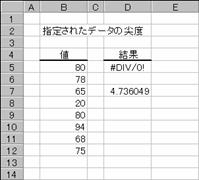
���j�t�q�s��
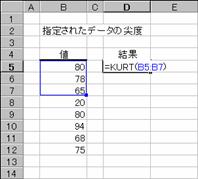
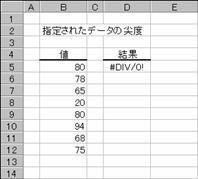
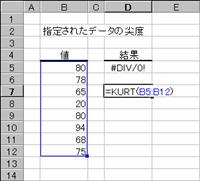
�����Ƃ��Ďw�肵���f�[�^�̐�x��Ԃ��B��x�Ƃ́A�ΏۂƂȂ�f�[�^�̕��z��W�����z�Ɣ�r���āA�x�����z�Ȑ��̑��ΓI�ȉs�p�x�܂��͕�����x��\�������l�ł��B
���� KURT(���l1, ���l2, ...)
���l11,���l2,... ��x���v�Z����l���w�肷��i�ő�R�O�܂ł�
�����Ƃ��Ďw�肵���z��܂��̓Z���͈͂ɁA������A�_���l�A�܂��͋Z�����܂܂�Ă���ꍇ�A�����͖�������܂��B�������A���l�Ƃ��� 0 (�[��) ���܂ރZ���͌v�Z�̑ΏۂƂȂ�܂��B4�ȏ�̃f�[�^��������Ă��Ȃ��ꍇ�A�܂��͕W�{�̕W������ 0 (�[��) �ɓ������ꍇ�A�G���[�l
#DIV/�O! ���Ԃ���܂��B
��x�͎��̂悤�ɒ�`����܂��B
�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A085Z
s �͕W�{�Ɋ�Â����W������\���܂��B
�g�p��
�m�`�n��������͂���
�m�a�n�����̌����S�ȉ��͌v�Z�s�\
 �@
�@
EX4A395Z�@�@�@�@�@�@�@�@�@�@�@�@EX4A396Z
 �@�@
�@�@
EX4A397Z�@�@�@�@�@�@�@�@�@�@�@�@�@EX4A398Z
�쐬�菇
�@���āA�ǂ����珑���n�߂�����̂ł��傤�B

 |